자언어 처리 프로젝트를 진행하다보면, 성능을 높이기 위해 고려되는 방법 중 하나로 "데이터 증강" 이 있다.
데이터 증강에도 여러가지 방법이 있는데, 하나씩 알아보면서 실제 모델을 만들고 패키지로 제공하려고 한다.

Paraphrasing-based methods
데이터를 증강하기 위해 아래 그림과 같이, 단어 레벨, 구문 레벨, 문장 레벨로 데이터를 증강하는 방법이 있다. 그 중, 첫번째로 Thasaurus방식에 대해 먼저 알아보고자 한다.

Thasaurus (유의어로 대체)
문장이 있을 때, 특정 단어를 비슷한 의미를 가진 단어로 대체하는 방법이 있다.
예를 들어, "나는 정말 굉장한 일을 하고 있어" 라는 문장이 주어졌을 때, "굉장한" 이라는 단어를 "엄청난" 이라는 단어로 바꾸는 것이다. 따라서 "나는 정말 엄청난 일을 하고 있어"라는 문장을 만들어 데이터를 증강하는 방식이다.
2019년도에 EMNLP에서 발표한 Easy Data Augmentation Techniques 논문에서도 첫번째로 이 태스크가 소개되었다. 이 논문에서는 문장에서 랜덤으로 stop words가 아닌 n 개의 단어들을 선택해 임의로 선택한 동의어들 중 하나로 바꾸도록 구현했다.
Semantic embeddings
이 방법은 유의어로 대체하려고 할 때, 범위가 제한적일 경우를 대비해 나온 방법이다. 이 방법은 pre-trained된 Glove, Word2Vec, FastText 등 단어 임베딩을 사용하여 바꾸려고 하는 단어를 코사인 거리가 가장 가까운 단어로 대체하는 방법이다.

Language models (MLM)
Pre-trained된 BERT, RoBERTa와 같은 모델을 활용하여 특정단어를 [MASK]처리한 후, [MASK]된 단어를 예측해 데이터를 증강하는 방식이다.

Rules
문장 내에 있는 단어를 룰 기반으로 대체하는 방법이다.

Back translation (역번역)
번역기를 사용해 한국어 문장을 특정 언어로 번역한 후, 번역된 문장을 다시 한국어로 번역하는 방법이다.

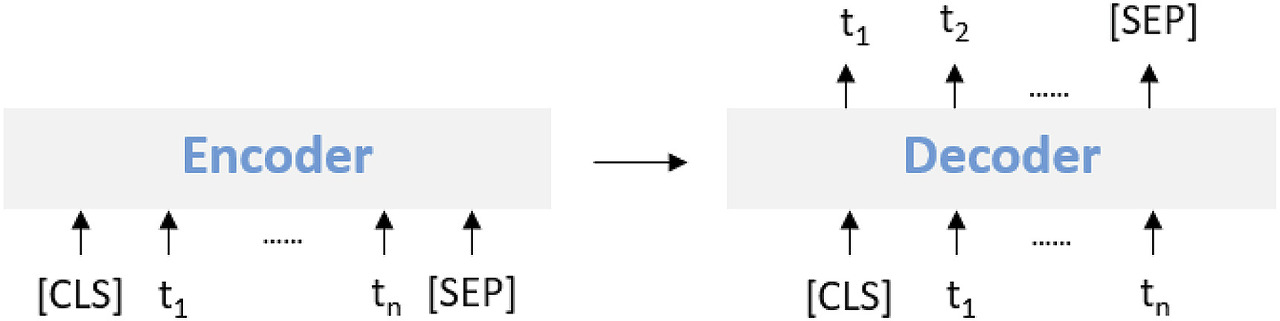
Model generation
Seq2Seq 모델을 활용해 데이터를 증강하는 방법이다.
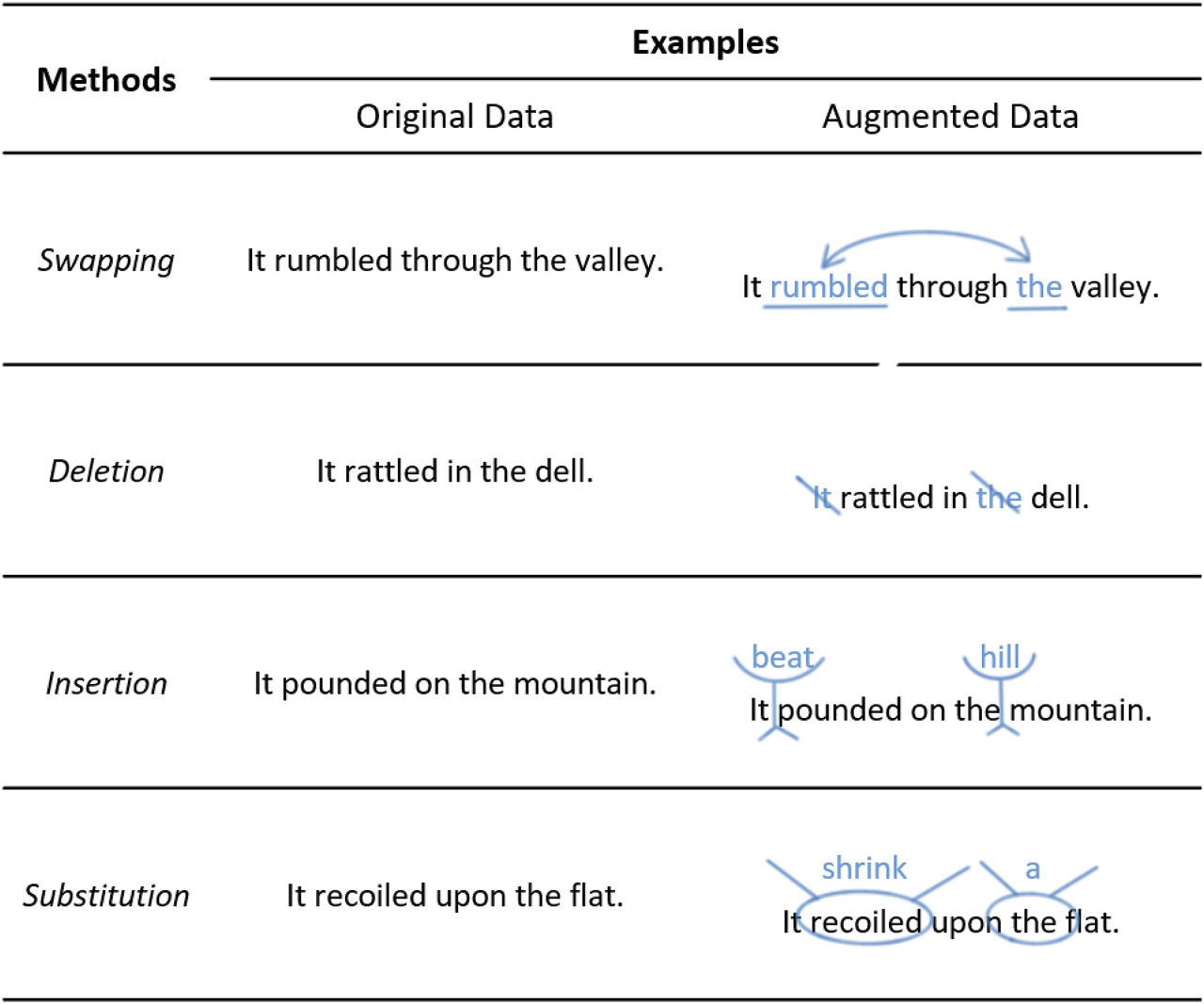
Noising-based methods
특정 단어를 추출해 바꾸거나 (Swapping), 특정 단어를 제거하거나 (Deletion), 특정 단어를 삽입하거나 (Insertion), 특정 단어를 대체하는 방식 (Substitution)이 있다.
Sampling-based methods
샘플링을 기반한 방법은 기존의 방식들과는 다르게 레이블 정보와 같은, 특정 태스크에 관련된 정보가 필요하다.
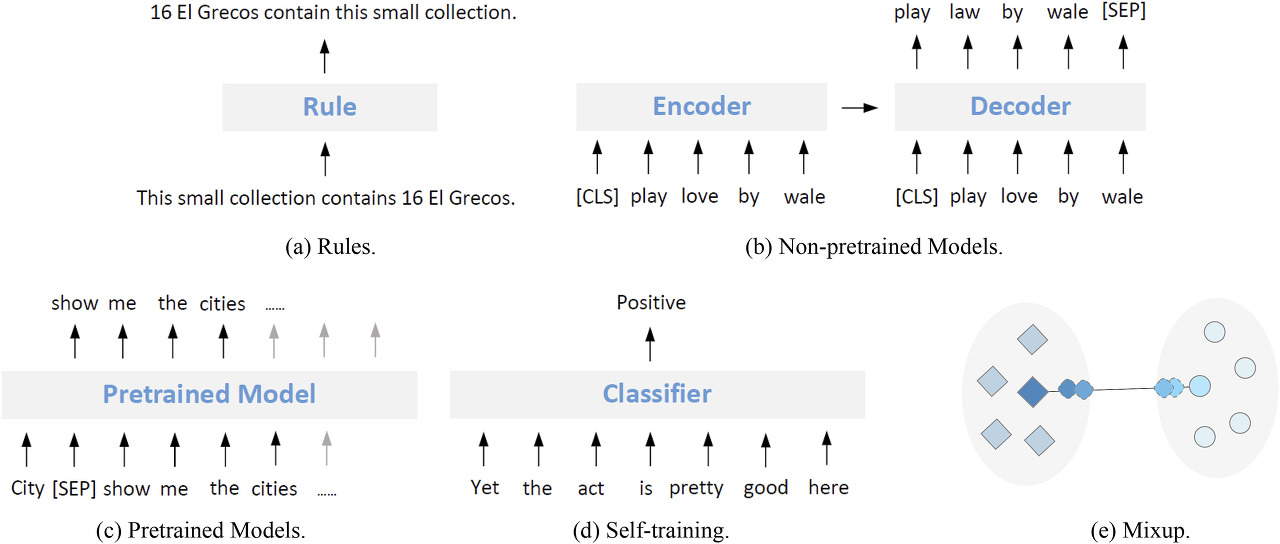
Rule
paraphrasing기반 방식과 마찬가지로 사람이 개입하여 룰을 기반으로 데이터를 증강하는 방법이다.
예를 들어, 현재형 문장을 수동태로 바꿀 수 있다. 즉, "This small collection contains 16 El Grecos."라는 문장이 주어질 경우 "16 El Grecos contain this small collection."로 바꾸는 것이다. 이때, 새롭게 생성된 문장의 label은 rule에 의해 결정된다.
Non-pretrained models
이 방식은 back translation의 아이디어를 포함하고 있다. 즉, Seq2Seq 모델을 활용해 학습시키고, target 문장으로 부터 source 문장을 생성하는 것이다. 이러한 Seq2Seq 모델은 target과 source의 매핑 구조를 학습한다. paraphrasing 방식과의 차이점은 paraphrasing 방식의 경우, 증강된 데이터가 원본 데이터와 유사한 문맥구조로 이루어진다는 것이다.
Pretrained models
Pretrain된 모델을 활용하여 주어진 label에 맞는 유사한 데이터 셋을 증강하는 방식이다. 따라서, GPT모델 등을 활용해 데이터를 증강할 수 있다.
Self-training
label이 없는 데이터를 활용하여 모델에 태운 후, label을 생성하여 데이터를 증강하는 방식이다.
Mixup
단어의 임베딩 값을 활용하여 데이터를 증강하는 방식이다. 예를들어, 각 단어의 representation vector와 weighted average를 취해서 만든 vector를 모델의 input으로 넣어 새로운 sentence representaion vector를 얻는 방식이 있다. 혹은, 기존 두 문장의 word representation vector들을 먼저 모델에 넣어 sentence representation vector를 얻은 뒤, 이를 weighted average를 취해 새로운 sentence representation vector를 얻는 방식이 있다.
그렇다면 어떤 방식을 활용해 데이터를 증강하는 것이 좋을까?
데이터를 증강할때, 문장의 의미를 너무 훼손하지 않으면서, 원본과 다른 문장을 만들어야 한다. 따라서 고려할 수 있는 방법은 아래와 같다.
- 번역 모델 fine-tuning하는 방법
- Huggingface에 공개된 NLLB 모델을 fine-tuning하여 backtranslation과정을 거쳐 데이터를 증강하는 방식이 있다.
- Pre-train 모델 기반 data augmentation
- 문장의 일부 어절을 [MASK] 토큰으로 치환한 뒤, pre-train 모델로 [MASK]를 복원하는 방식이다.
- 혹은 [MASK] 토큰을 문장 내 무작위로 삽입한 뒤, pre-train 기반 모델로 [MASK]를 복원하는 방식이다.
- 이 방식을 활용하면 문맥을 고려한 문장을 만들 수 있다는 장점이 있다.
- 말투 변경
- Smile gate에서 공개된 데이터셋을 기반으로 말투 변경 모델을 만들어 데이터를 증강할 수 있다.
따라서, 위 방식을 활용해 하나씩 모델을 개발하고자 한다. 자세한 모델 개발 과정은 다음 포스팅에서 이어진다.
Reference
https://www.sciencedirect.com/science/article/pii/S2666651022000080
댓글