
Language Model은 크게 4가지 부류로 나눠서 설명할 수 있다.
-
Statisical Language Modeling (SLM): 1990년도에 나와 단순히 n-gram 기법으로 주변 문맥을 고려해 다음에 어떤 단어가 올지 예측하는 방법이다.
-
Neural Language Models (NLM): RNNs, LSTMs, GRUs, word2vec과 같이 neural network를 사용한 기법이다.
위 4가지 부류 중, 그림에서 보여주듯이 최근 1년간 많은 Large Language Model이 소개 되었다. 하지만 노란색으로 색칠되어 있는 모델만 모델 학습 과정, 데이터 셋, 모델 구조 등 전반에 걸쳐 상세한 내용과 어떤 파라미터를 활용했는지 알 수 있다. (색칠되어 있지 않은 모델은 논문으로만 공개되어 있을 뿐 모델 파라미터에 대한 접근이 불가능하다.)
Meta에서 LLaMA를 오픈소스로 공개하기 이전
LLM인 ChatGPT가 2022년도 11~12월에 나타난 이후 일반 사람들에게는 정말 혁신적이었다. 반면, 연구자들은 LLM은 연구조차 할 수 없는 영역이었다. 그 이유는 공개된 모델 크기는 최소 175B었기 때문에 모델을 다운로드 받을 수 조차 없었기 때문이다. 또한 해당 모델을 Inference 하기 위해 최소 GPU가 4대정도 필요하기 때문이다.
따라서 연구자들은 LLM을 API를 통한 접근만 가능할 뿐, 연구는 일부 대기업 (Meta, OpenAI, Microsoft)에서만 할 수 있게 되었다.
LLaMA 공개
하지만, Meta에서 모델의 파라미터, 학습 방법론에 대한 상세한 내용을 담아 LLaMA를 공개하게 되어 연구자들에게 한줄기의 빛이 되었다.
그 이유는, LLaMA는 7B의 모델 크기로, 기존에 발표 되었던 GPT-3, Chinchilla 등 초 거대 LLM 모델과 비교했을 때 비슷한 성능을 내거나 혹은 더 우수한 성능을 도출했기 때문이다. 따라서 적은 비용으로 공개된 LLM을 효과적으로 Tuning할 수 있는 계기가 되었다.
위 그림과 같이 LLaMA가 공개된 이후 LLaMA를 기반으로 수 많은 모델들이 학습되었고 공개되었다.
LLaMA 훈련을 위해 필요한 것?
> 추가 학습을 위한 데이터 셋 (데이터셋 수집을 위한 대안: Self Instruct)
그렇다면 LLaMA 훈련을 위해 데이터셋은 어떻게 마련해야 할까? 이때, 고려할 수 있는 방법에 Self Instruct란 방법론을 활용할 수 있다. 이 방법론이 제안된 배경은 "instruction-tuned" 모델이 사람이 만든 학습 데이터의 품질과 양에 의존하기 때문에 다양성과 창의성을 제한받을 수 있기 때문에 이 문제점을 극복하기 위한 것이다.
따라서 대량의 instruction 데이터셋을 생성하기 위해 사람이 아닌 LLM을 활용했다. 이로써
- API 비용(20만원)만 부담하여 SFT Dataset을 확보 가능
- 52,000건의 Prompt (모델 입력)
- 82,000건의 Instance (응답)
- 좋은 SFT Dataset의 조건
- 다양한 표현으로 작성된 Prompt
- Prompt에 대해 적절히 작성된 응답
- GPT-3 API만을 이용해 모든 작업 수행
Self Instruct 과정?
0. Task Pool 초기화
사람이 작성한 instruction seed 세트로 시작하는 반복적인 bootstraping알고리즘이다. seed 데이터 셋은 새로운 instruction과 해당 입력-출력 인스턴스를 생성하기 위해 LLM의 프롬프트로 제공된다.
(이때, Prompt-Instance 조합은 사람이 최초로 생성해야 한다.)
※ instruction seed 세트 예시: https://github.com/yizhongw/self-instruct/blob/main/data/seed_tasks.jsonl
GitHub - yizhongw/self-instruct: Aligning pretrained language models with instruction data generated by themselves.
Aligning pretrained language models with instruction data generated by themselves. - GitHub - yizhongw/self-instruct: Aligning pretrained language models with instruction data generated by themselves.
github.com
1. Instruction Generation
사람이 생성한 6개의 샘플과 GPT가 생성한 2개의 샘플을 섞어 Instruction을 생성하도록 한다. 따라서 task 8까지 입력으로 넣어준 다음 task 9는 모델이 생성하도록 하는 것이다.
2. Classification Task Identification
이후 생성된 task가 분류문제인지 아닌지 GPT3의 few-shot을 활용한다. 이때, instricton seed 세트는 분류 문제를 가지는 12개의 instruction과 19개의 instruction은 분류 문제가 아닌 것으로 정의되어있는 것을 예시로 활용한다.
분류 문제가 아닌 instuction에 대해선, 입력 우선 방식으로 접근했다. 따라서 프롬프트가 instance를 먼저 생성한 다음 이에 상응하는 output을 생성하도록 했다.
Classification Task가 있는 경우에는 출력 우선 접근 방식에 사용되는 프롬프트를 활용한다. 모델에 먼저 클래스 레이블을 생성하라는 메시지가 표시된다. 이후 클래스 레이블을 먼저 생성한 다음 해당 입력을 생성하라는 메시지가 표시된다. 이 프롬프트는 분류 작업의 인스턴스를 생성하는데 사용된다.

3. Filtering
데이터의 다양성을 위해 ROUGE 스코어를 활용하여 0.7 미만일 경우 데이터 풀에 추가하도록 했다. 또 언어 모델에만 적용시키기 위해 image, picture, graph와 같은 특정 키워드가 포함되어 있을 경우 데이터셋에서 제외하도록 했다.
위 1~3 과정을 반복해서 데이터 셋을 만든다음 fine-tuning하여 활용하면 된다.
(그렇다면 Self-Instruct를 활용한 결과는 어떨까? Self-Instruct를 기반한 데이터 셋의 정확도는 논문에서 58% 정도라고 한다. 정확도 측면에서는 떨어지지만, 실제 모델을 학습하는 데이터 셋으로 활용할 때에는 좋은 성능을 낼 수 있다고 저자는 말한다.)
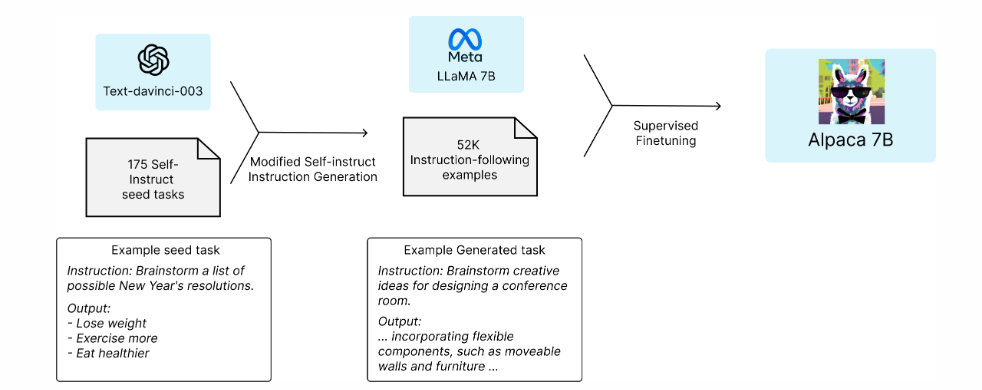
앞서 소개한 Self-Instruct 방식을 일부 활용하여 LLaMA를 fine-tuning 한 모델이 바로 Alpaca이다.
Alpaca의 등장
그럼 Alpaca에 대해 자세히 알아보려고 한다. Alpaca는 LLaMA 7B 모델에서 fine-tuned된 모델이다. 해당 모델은 OpenAI의 GPT-3.5 (text-davinci-003) 모델과 유사하게 작동하면서 저렴한 비용으로 학습시킬 수 있다.
해당 모델이 공개된 이유는 GPT-3.5 (text-davinci-003), ChatGPT, Claude, and Bing Chat과 같이 Instruction-following 모델은 점점더 진화하고 있다. 이러한 모델이 널리 배포됨에도 불구하고 instruction-following 모델은 잘못된 정보를 생성하고, 사회적인 편견 그리고 유해한 컨텐츠를 생성하는 등 여전히 많은 결함을 내포하고 있다.
이러한 문제를 최대한 해결하기 위해 스탠포드는 학계의 참여가 중요하다고 생각하였지만, OpenAI의 GPT-3.5와 같은 모델이 비공개로 되어있기 때문에 instruction-following 모델들은 학계에서 연구하기가 힘들었다.
따라서 이번에 Alpaca라는 instruction-following 모델을 공개함으로써 해당 연구 분야의 발전에 기여하고자 한다. 이 모델은 Meta에서 공개한 LLaMA 7B 모델을 fine-tuning한 것이고 fine-tuning하기 위한 데이터 셋으로 text-davinci-003을 사용해 self-instruct로 생성된 52K개의 데이터로 학습하였다.
해당 모델은 상업적으로 활용할 수 없으며, OpenAI와 경쟁하는 모델을 개발하는 것 또한 금지되어 있다.
Training recipe
데이터의 경우, self-instruct 방식을 기반으로 instruction-following 데모를 생성했다. Self-instruct에서 소개된 방식과 같이 사람이 작성한 175개의 instruction-output 쌍을 시작으로 text-davinci-003에 문맥 내 예제로서 seed set을 사용해 더 많은 instruction을 생성하도록 했다. (자세한 내용은 github에 있다.) 이때, self-instruct에서 소개된 방식과는 조금 다르게 생성 파이프라인을 간소화하여 개선하였으며 비용도 절감했다. (500달러 미만의 비용을 썼다.)
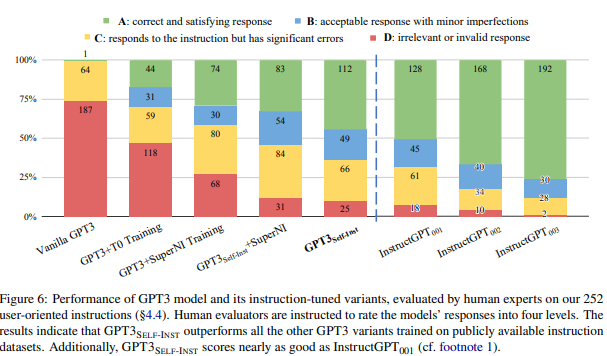
Preliminary evaluation
해당 모델을 평가하기 위해 5명의 학생이 평가를 진행했다. 결과를 보면 text-davinci-003과 비교했을 때 두 모델 성능이 매우 유사한 것을 볼 수 있다.
모델 크기가 작고, instruction-following 데이터셋이 작은것을 고려함에도 결과는 놀랍다.
Known limitations
하지만, Alpaca는 hallucination, 유해성, 고정관념에서 몇가지 결함을 보인다. 특히 hallucination에서 alpaca는 text-davinci-003과 비교했을 때 잘 작동하지 않는것을 볼 수 있다.
따라서 Alpaca는 이러한 중요한 결함을 연구하는데 기초가 되는 모델이므로 앞으로 instruction-following 모델과 인간 가치에 부합하는 모델로써 추가적인 연구를 촉진할 수 있을 것이다.
Release Decision
한편으로는, 적은 비용으로 fine-tuning할 수 있는 모델과 데이터셋이 공개됨으로써 stochastic parrot 문제를 야기할 가능성도 높아지고, 의도적으로 가짜뉴스를 만드는 경우 사회가 혼란스러워 질 수 있을 것 같다는 우려도 있을것이라고 생각했다.
마찬가지로 stanford에서도 이러한 걱정이 있어 위험을 완화하기 위한 전략을 내세웠다.
첫째, OpenAI의 콘텐츠 중재 API를 사용하여 콘텐츠 필터링을 통해 유해 콘텐츠를 필터링 한다. 둘째, 다른 사람들이 생성한 모델이 7B 출력인지 여부를 확률적으로 감지할 수 있도록 모델의 모든 출력에 워터마크를 표시한다. 마지막으로 데모 사용에는 엄격한 이용 약관이 적용되며, 비상업적 용도로만 사용해야 한다.
Future directions
Alpaca의 방향성은 아래와 같이 3가지로 제시되고 있다.
- Evaluation: 보다 엄격하게 평가해야한다. 따라서 보다 생성적이고 instruction-following을 따르는 시나리오를 포착할 수 있도록 발전해야 한다.
- Safety: 위험성을 더 연구하며 안전성을 개선해야 한다.
- Understanding: training recipe에서 기능들이 어떻게 발생하는지 더 잘 이해해야 한다. 기본 모델에는 어떠한 특성이 필요한지? 확장하면 어떤 일이 일어나는지? instruction data의 어떤 속성이 필요한지? text-davinci-003에 self-instruct를 사용하는 방법 대신 어떤 것을 사용할 수 있는지?
Reference
- Self-Instruct: https://arxiv.org/pdf/2212.10560.pdf
- https://crfm.stanford.edu/2023/03/13/alpaca.html
이렇게 LLaMA부터 Alpaca까지 모델을 살펴보았다. 이전에는 LLM은 빅 테크 기업에서만 활용할 수 있기 때문에 분명한 한계점과 높은 벽을 느꼈었다. 하지만, Self-Instruct와 같이 양질의 데이터 셋을 구축할 수 있는 아이디어 hallucination을 대비할 수 있는 아이디어 혹은 LLM을 최적화해서 학습 할 수 있는 아이디어 등 또 다른 연구 주제들이 생겨날 듯 하다.
그럼에도 불구하고, 사실 빅 테크 기업의 RLHF 기반 모델을 뛰어넘기는 힘들 것 같다. Alpaca를 기점으로 생성 모델의 한계점들을 극복하는 방안들이 제시되면서 빅 테크 기업에선 이 기법을 활용해 RLHF 모델을 더 발전시켜 결국 강화학습을 기반한 언어모델이 LLM을 선두하지 않을까 라고 조심스럽게 예측해본다.
'Natural Language Processing > Large Language Model (LLM)' 카테고리의 다른 글
| [Paper 간단 리뷰] Platypus: Quick, Cheap, and Powerful Refinement of LLMs (0) | 2023.08.18 |
|---|---|
| [LLM 평가 지표] Elo Ratings으로 LLM모델들을 랭킹하는 방법 (1) | 2023.07.03 |
| [LLM 모델 간단 Review] LLaMA: Open and Efficient Foundation Language Models (0) | 2023.06.08 |
| [강의 후기] 한국어 LLM 민주화의 시작 KoAlpaca! - 이준범 (0) | 2023.06.01 |
| Illustrating Reinforcement Learning from Human Feedback (RLHF)이란 (2) | 2023.05.09 |



댓글