Overview
TRADE 모델
- Multi-domain dialogue state tracking을 진행
- Ontology-free (Open vocabulary) DST model
- Encoder와 Decoder를 쌓아서 만든 모델
TRADE 모델의 contribution
- Multi-domain dataset에서 성능을 높이기 위해 domain간 tracking된 정보를 공유
- Domain간 slot의 value를 공유하게 함
- 여러 domain 데이터를 하나의 모델로 학습 (=parameter sharing)
- Multi-turn mapping problem을 해결하기위해 copy mechanism을 사용하여 긴 길이의 dialogue history에서 등장한 slot과 value를 적절하게 tracking함
- Unseen domain에서 slot을 tracking 할 수 있도록 함
- Knowledge transfer를 통해 Zero-shot setting에서도 준수한 성능을 보임
- 데이터가 매우 작은 domain에서도 준수한 성능을 보임 (few-shot setting) -> Continual learning의 아이디어를 차용하여 previous domain에서 학습한 정보를 보존함
Model
- Utterance Encoder, Slot Gate, State Generator로 구성된 모델

Utterance Encoder
- Bi-directional GRU (어떤 종류의 Encoder로도 대체 가능)
- Input은 dialogue history의 모든 단어 concatenation
- 문맥을 고려하기 위해서는 특정 현재 시점 기준으로 일정 길이의 dialogue history turn이 필요
- Output은 dialogue history represenation

대화가 User_1st - Bot_1st -> User_2nd - Bot_2nd -> User_3rd - Bot_3rd -> User_4th 순으로 구성되어있다고 가정하면,
이때, t=1의 경우 발화가 시작된 시점의 User_1st - Bot_1st 의 하나의 발화 쌍이라고 생각하면 된다.
따라서 Utterance Encoder에 Bot_1st 과 User_1st 의 대화를 concatenate해서 Input으로 설정한 것이다.
2번째 시점(t=2)에서는 Bot_1st -> User_2nd의 대화를 concatenate해서 input으로 설정한 것이다.
마찬가지로 3번째 시점(t=3)에서는 User_2nd - Bot_2nd 의 대화를 concatenate해서 input으로 설정한 것이다. 이렇게 sliding방식을 활용해 대화를 concatenate하여 input으로 설정한다.
State Generator

- Bi-directional GRU decoder
- Copy mechanism을 통해 input dialogue의 정보를 활용하여 slot value를 generate하는 것이다.
- Decoding은 (domain, slot) pair별 j회 이루어진다. (slot별 value를 generate해야하기 때문)
- Generator는 domain, slot의 word embedding을 input으로 받아 h_dec_j를 생성한다.
- Soft-gated 방법론인 Pointer-Generator copy를 활용하여 vocab의 분포와 dialogue history의 분포를 하나의 분포로 결합한다.
- 아래 이미지에서 P_vocab_jk는 utterance encoder에서 나타나는 (domain, slot) j번째, k번째 value 생성 차례의 vocab 확률 분포를 나타낸다. 이때, E는 학습 가능한 임베딩 (vocab개수 * dimension)을 나타낸다. 따라서 hidden vector를 활용해서 softmax를 vocab의 개수만큼 태워서 도출한다.
- 아래 이미지에서 P_history_jk는 utterance encoder에서 나타나는 (domain, slot) j번째, k번째 value 생성 차례의 history확률 분포를 나타낸다. 이때, H_t는 Encode된 dialogue history를 나타낸다.
- Final Output은 기존의 P_vocab_jk와 P_history_jk를 새로운 P_gen_jk 새로운 값을 통해 weighted sum을 하여 구하는 것이다.
- 이때, P_gen_jk은 학습 가능한 값으로, weighted sum하는 부분이 pointer generator역할을 하는 부분이라고 보면된다.
- P_gen_jk을 구하기 위해 아래 3가지 값을 곱한 에 sigmoid를 취해야 한다.
- h_dec_jk: (domain, slot) pair와 utterance encoding을 가지고 만들어진 hidden state vector
- word embedding
- context vector: P_history_jk*H_t
- 이렇게 pointer-generator를 활용함으로써 predefined vocabulary가 아니더라도 dialogue history로 부터 단어 생성이 가능하다는 장점이 있다.
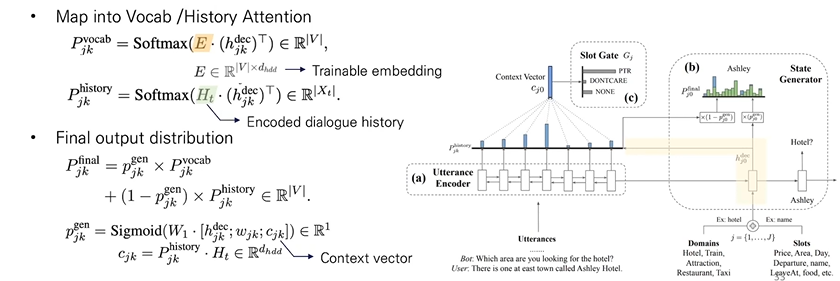
- 따라서 Input은 domain과 slot의 summed embedding이 되며, 이에따른 Output은 (domain, slot)에 알맞는 value값이 된다.
State Generator
- Domain이 1개인 경우 (single-domain DST) slot의 개수가 적어 tracking하는데 문제가 없음
- 하지만 multi-domain DST에서는 domain당 slot 조합 개수가 많아진다는 문제가 있음
- Slot Gate는 context vector로 부터 slot의 존재 여부를 알아내는 역할을 함
- 따라서 아래 이미지와 같이, context vector와 weighted를 곱한다음 softmax 값을 취해 PTR, DONCARE, NONE중 하나로 분류하는 것이다.
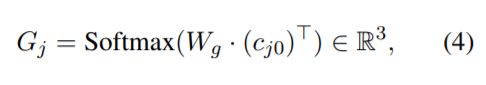

정리해서 말하자면, Slot Generator에서 생성된 h_dec_j0 (대화와 슬롯의 관계 정보)를 통해 p_history를 만들고, 이를 사용해 c_j0 (context vector)를 만든다. Slot Gate는 contect vector (첫번째 디코더의 hidden state) 로부터 slot의 존재 여부를 알아내는 역할을 수행한다.
따라서,
- PTR, DONCARE, NONE 3가지 label로 출력하고
- PTR이 나오면 value를 Generate하고
- DONCARE, NONE이 나오면 무시하는 방법이다.
Optimization
- Slot gate와 state generator에서 loss가 발생한다.
- Slot gate loss: 아래 두 항목에 대해 cross entropy를 구한 값
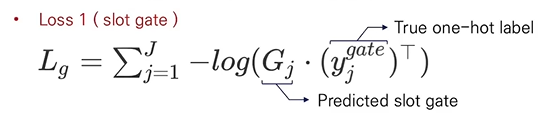
- State generator loss: 아래 항목에 대해 cross entropy를 구한 값
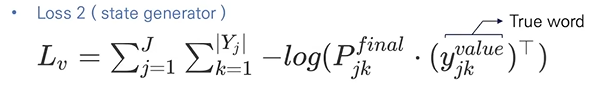
- Final loss: 위 두가지 loss에 대해 weighted-sum을 구한 값
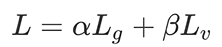
Result
Dataset
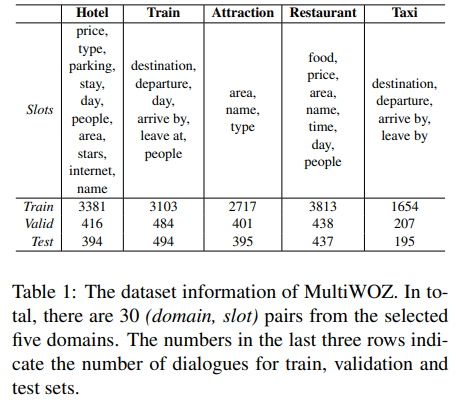
5개의 domain에 대해서 실험을 진행하였고, domain별로 slot의 개수가 상이함.
domain뱔러 겹치는 slot이 발생하기 때문에 domain별 성능을 높여보기 위해 학습 시 파라미터를 쉐어하도록 하였고, glove embedding을 활용함.
Metric
- Joint goal accuracy: 각 dialogue turn에서 생기는 모든 GT triple과 예측된 값이 matching될 때의 정확도
- Slot accuracy: 각각의 triple과 GT가 matching 될 때의 정확도
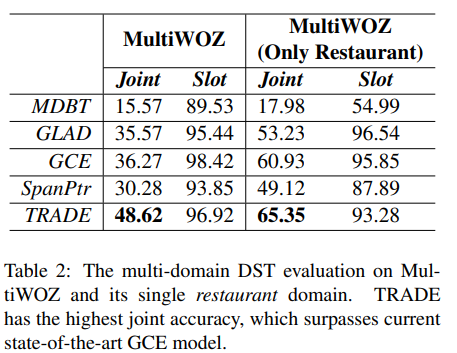
새로운 domain 데이터가 추가될때의 성능
1) Zero-shot experiment
- Zero-shot: 데이터에서 한개의 domain만 제외하고 학습을 진행한 후 학습에 사용하지 않은 데이터로 성능을 비교
- Trained Single: Single domain DST와 같은 설정
- 이때, taxi의 결과가 높은 이유는 train과 동일한 slot을 많이 공유하고 있기 때문이다.
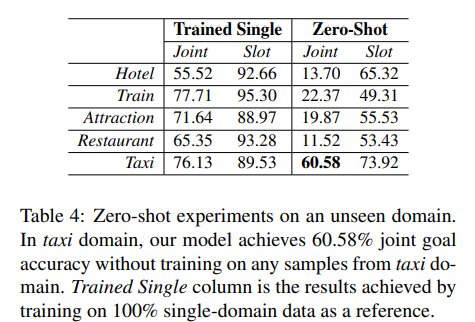
2) Expanding DST for Few-shot Domain
- 매우 적은 양의 new domain 샘플 데이터를 활용하여 학습 진행
- DST model의 knowledge transfer 능력을 확인
- 이러한 과정을 few-shot domain expansion이라고 정의
- Knowledge transfer를 위해 새로운 loss function을 정의하고 실험을 진행
- 결국, source domain에서 학습한 지식을 target domain이 잊어버리지 않도록 학습하는 것이 목적이다.

이때, 위 목적을 진행하기 위한 task가 존재한다. Continual learning 문제로 정의해 해결할 수 있다.
DST ----- Adapt ----> Continual Learning
- Domain - task
- New Domain - New task
이렇게, Domain expansion을 통해서 얻는 장점은 2가지가 있다.
- 새로운 Domain이 등장했을 때 적은양의 데이터를 활용하여 빠르게 적용(quickly adapt)이 가능
- Data가 더이상 사용할 수 없는 상태이거나, Retraining에 오랜 시간이 걸리는 경우 용이
그렇다면 continual learning의 가법에는 무엇이 있을까?
- Elastic weight consolidation (EWC)에서 사용하는 loss term
기존 target loss term에 Regularizer역할을 하는 새로운 term을 더한 형태로 이때, 새로운 term은 fisher information matrix를 활용함
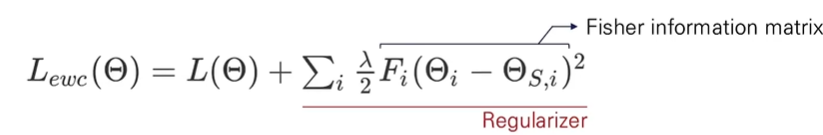
- Fisher information as Regularizer
: target에서 source를 뺀 형태로 사
: 새로운 domain을 학습할 때 penalty의 역할
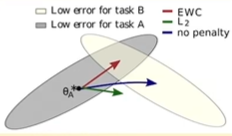
: 기존 domain과 새로운 domain에서 모두 낮은 error를 가질 수 있게 도와줌
- 계산상의 이점
: Likelihood function으로부터 FIM을 유도할 수 있는데, Hessian matrix로 근사 가능
: Loss의 2차 미분값이 minimum에 가까워 계산상 이점이 있음
: 1차 미분으로 쉽게 계산 가
- Gradient episodic memory (GEM)
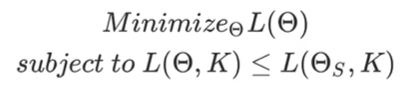
: target의 loss를 줄이는식으로 목적함수를 설정. 제약식의 경우, target의 loss term이 source의 loss term보다 작거나 같도록 강제함
- 제약조건을 추가해서 Loss값을 줄이려면 제약식을 목적함수에 penalty 항으로 적용해야함
- GEM에서 정의한 제약식은 풀기 복잡하기때문에 locally linear하게 가정
- 제약식을 Quadratic Program (QP)의 form으로 바꾸어 줌.
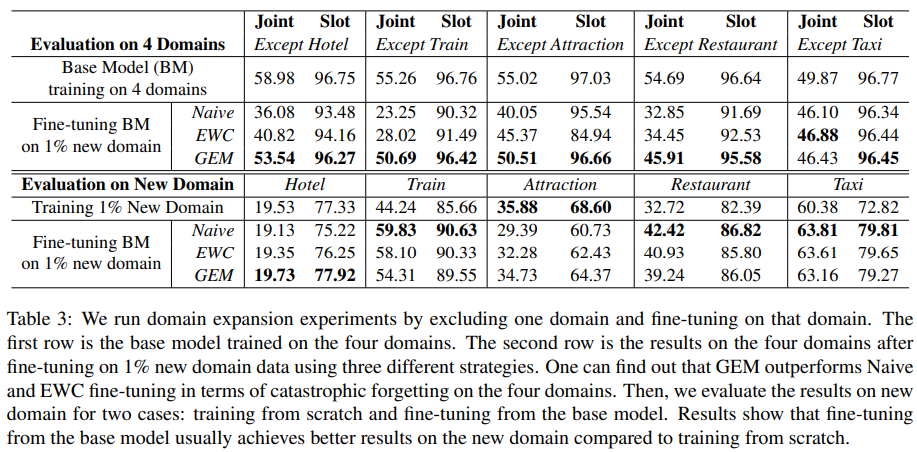
따라서 위에 언급된 loss에 기반해 결과를 보면 baseline 모델을 하나 만들고, 학습한 다음 다시 새로운 loss term을 활용해 fine-tuning을 진행함.
Conclusion
- Pointer-Generator 구조를 활용하여 학습시 보지 못했던 단어도 State Generator에서 생성 가능
- Multi-domain 성능을 높이기 위해 Domain간 파라미터를 쉐어하고, Pretrained word embedding을 사용함
- Zero-shot setting에서 준수한 성능을 보임
- Few-shot setting에서 knowledge transfer를 확인하기 위해 Continual learning technique 활용
아래 유투브 영상을 기반으로 작성된 글 입니다.
'Natural Language Processing > Dialogue State Tracking' 카테고리의 다른 글
| [Dialogue State Tracking] input, output, 목적, challenge, 한계점 (0) | 2023.07.13 |
|---|---|
| [Dialogue System] Dialogue System - Task Oriented dialogue system (0) | 2023.07.12 |


댓글