배경
- 좋은 텍스트 생성 모델을 만들기 위해 BLEU 또는 ROUGE와 같은 사람이 직접 평가한 메트릭을 정의해 평기를 진행해왔다.
- 따라서 생성된 텍스트에 대해 인간의 피드백을 성능 측정에 활용하고, 피드백을 기반으로 손실을 사용해 모델을 최적화 하면 어떨까? 라는 아이디어에서 RLHF(Reinforcement Learning from Human Feedback)의 개념이 나왔다.
- 아이디어의 기본은 강화 학습의 방법을 사용하여 사람의 피드백으로 언어 모델을 직접 최적화 한 것이다.
- 이 개념은 ChatGPT에서 사용되었다.
RLHF: Let’s take it step by step
인간 피드백을 통한 강화학습은 어려운 컨셉이다. 왜냐하면 다중 모델의 훈련 과정과 각 단계마다 다른 배포 과정을 거쳐야 하기 때문이다. 이해하기 쉽도록 이번 글에선 훈련 과정을 세 단계로 분류해서 설명할 예정이다.
- Pretraining LM (language model)
- 데이터 수집 및 리워드 모델 학습
- 강화학습을 활용해 LM모델 fine-tunning
Pretraining language models
RLHF는 기존에 사전 훈련된 언어 모델을 사용한다. OpenAI는 최초로 RLHF를 활용한 InstructGPT에 더 작은 버전의 GPT-3를 활용했다. Anthropic은 100만에서 520억개의 파라미터를 갖는 트랜스포머 모델을 사용했다. DeepMind는 2800억개의 파라미터를 갖는 Gopher를 사용했다.
이때, "어떤 pretraining된 모델을 활용할 것인가"에 대해선 정답이 없다.
어떤 사전 훈련된 언어 모델을 사용활용할지 결정했다면, 다음으로 language model를 활용해서 reward model(RM)을 학습시키기 위한 데이터를 만들어야 한다.

Reward model training
RM(사람의 보정으로 생성된 reward model)을 생성하는 것은 RLHF연구의 시작이다.
근본적인 목표는 문장 시퀀스가 주어질 때, 인간의 선호도를 기반한 스칼라 리워드를 얻음으로써 모델 혹은 시스템을 얻는 방식 이다. 시스템은 end-to-end LM이거나 reward를 출력하는 모듈식 시스템일 수 있다. (ex. 모델이 결과값에 랭킹을 매기고, 랭킹이 리워드로 변환되는 방식을 말함) 결과값을 의미하는 scalar reward이고 기존 RL 알고리즘과 이후 RLHF 프로세스에 매우 중요한 개념 이다.
Reward 모델링을 위한 LM들은 fine-tunning된 LM혹은 처음부터 훈련된 LM일 수 있다. Anthropic의 경우 fine-tunning 보다 모델을 초기화 한 이후 pretrining하는 방식이 더 효율적이라는 것을 알았기 때문이다.
RM에 대한 프롬프트 생성 쌍의 훈련 데이터는 사전에 정의된 데이터 셋에서 프롬프트 셋을 샘플링하여 생성된다. (데이터 셋은 AWS Mechanical Turk나 OpenAI로 부터 얻을 수 있다.)
프롬프트는 초기 언어 모델을 통해 전달되어 새로운 텍스트를 생성한다.
Human annotator는 LM에서 생성된 텍스트의 순서를 라벨링 한다. 초기 RM을 생성하기 위해 사람이 각 텍스트에 스칼라 점수를 직접 입력해야한다고 생각하지만, 쉽지 않다. 왜냐하면, 사람마다 문장을 바라보는 생각이 다르기 때문에 점수가 보정되지 않고 오히려 노이즈가 발생할 수 있기 때문이다. 따라서 여러 모델로 부터 나온 결과에 대해 성능을 비교할 때, 순위를 활용하여 정규화된 데이터 셋을 만든다.
텍스트의 순위를 매기는 방법에는 여러가지가 있다. 가장 좋은 방법은 사용자가 동일한 프롬프트에서 조건이 지정된 두 언어 모델에서 생성된 텍스트를 비교하도록 하는 것이다. 1:1로 모델의 출력을 비교함으로써 Elo Rating System을 활용해 모델 결과에 대해 상대적으로 순위를 생성할 수 있다. 이러한 순위 지정 방법(Elo Rating System 뿐만 아니라 다양한)은 훈련을 위한 스칼리 보상 신호로 정규화 된다.
- Elo Rating System이란?
- 승/패로 나뉘는 시합에 있어서, 선수의 실력을 승률에 따라 점수화하여 순위를 매기는 방식
- 따라서 레이팅이 자기보다 높은 사람에게 이기면 확 오르고, 레이팅이 자기보다 낮은 사람에게 이기면 조금 오른다.
- https://allcalc.org/16613
이 프로세스의 흥미로운 점은 현재까지 가장 성공한 RLHF 시스템이 텍스트 생성에 상대적으로 다양한 크기의 reward LM을 사용했다는 점이다. (OpenAI 175B LM, 6B reward model, Anthropic used LM and reward models from 10B to 52B, DeepMind uses 70B Chinchilla models for both LM and reward). 직관적으로 이러한 모델들은 텍스트를 생성하기 위해 모델이 필요한 것처럼, 주어진 텍스트를 이해할 수 있는 유사한 능력을 가져야 한다.
RLHF 시스템은 텍스트를 생성하는 데 사용할 수 있는 초기 언어 모델과 모든 텍스트를 가져와서 인간이 얼마나 잘 인식하는지 점수를 할당하는 선호 모델을 가지고 있다. 다음으로, 보상 모델과 관련하여 원래 언어 모델을 최적화하기 위해 강화 학습(RL)을 사용한다.
Fine-tuning with RL
강화학습을 활용해 언어 모델을 학습시키는 것은 오랫동안 엔지니어링과 알고리즘적인 이유로 불가능하다고 생각했을 것이다. 초기에 policy-gradient RL algorithm, Proximal Policy Optimization (PPO)을 활용해 초기 LM복사본의 일부 혹은 전체 매개 변수를 미세조정했었다.
LM의 파라미터들은 고정되어 있었다. 왜냐하면 전처 10B 혹은 100B+ 파라미터들을 fine-tunning하는 것은 비싸기 때문이다. 따라서 PPO는 오랫동안 사용되어 왔었다. 이 방법은 RLHF에 대한 분산 훈련을 적용하는데 근간이 되었다고 볼 수 있다. RLHF를 수행하기 위한 많은 RL 발전은 이러한 large model을 업데이트 하는 방법에 큰 도움이 되었기 때문이다.
RL을 활용해 fine-tunning하는 방법에 대해 알아보겠다.
첫번째, policy는 언어 모델이다. prompt가 입력되면 문장을 리턴한다. policy에 대한 action space는 언어모델에 상응하는 모든 토큰들이고 observative space는 input 토큰 순서들에 대한 분포다. Reward function은 preference 모델과 정책 전환에 대한 제약조건의 조합이다.
Reward function은 모든 모델을 하나의 RLHF 프로세스로 결합하는 곳이다. 데이터 셋에서 prompt x가 주어지면, 두개의 텍스트 y1, y2가 생성된다. 하나는 초기 언어 모델에서 다른 하나는 반복되는 fine-tunning 정책에서 생성된다. 현재 정책으로부터 오는 텍스트는 preference model에 통과되어 “preferability”라는 스칼라 값을 리턴한다(rθ). 이 텍스트는 초기 모델의 텍스트와 비교하여 두 모델 간의 차이에 대한 패널티를 계산한다.
OpenAI, Anthropic, DeepMind에서 이 패널티는 토큰에 대한 분포 시퀀스 간의 Kullback-Leibler(KL) 차이를 계산하여 확장된 버전으로 설계되었다.
- 쿨백-라이블러 발산 (Kullback–Leibler divergence, KLD)
- 두 확률 분포의 차이를 계산하는 데에 사용하는 함수로, 어떤 이상적인 분포에 대해, 그 분포를 근사하는 다른 분포를 사용해 샘플링을 할 경우 발생할 수 있는 정보 엔트로피 차이를 계산한다. (거리 개념이 아님)상대 엔트로프(relative entropy), information gain, information divergence라고도 함
- 자세한 설명: https://hyunw.kim/blog/2017/10/27/KL_divergence.html
KL 발산항은 RL 정책이 각 훈련 배치가 있는 초기 사전 훈련된 모델에서 크게 벗어나지 않도록 패널티를 준다. 이는 모델이 일관성이 있는 텍스트 snippets을 출력하도록 하는데 유용하다. 이 패널티가 없을 경우 횡설수설한 텍스트를 생성하지만 높은 reward를 제공하기 위해 RM을 속일 수 있다. 최종적인 RL을 업데이트 하도록 보내지는 최종 보상(*r)은 다음 수식이다. r=r_θ−λr_*KL.
일부 RLHF 시스템은 reward function에 추가 조건을 추가했다. 예를 들어, OpenAI는 pre-training gradients를 (human annotation set로 부터 온) PPO에 대한 업데이트 규칙에 혼합하여 InstructGPT에서 성공적으로 실험했다. RLHF가 더 연구됨에 따라 이 reward function의 공식은 계속 진화할 것이다.
마지막으로, update rule은 현재 데이터 배치에서 reward metrics을 최대화 하는 PPO의 매개변수를 업데이트 하는 것이다. (이때, PPO는 정책에 따라 실행된다. 즉 파라미터들이 prompt-generation쌍 배치로만 업데이트 된다.)
PPO는 그레이디언트의 제약 조건을 사용하여 업데이트 단계가 학습 프로세스를 불안정하게 하지 않도록 하는 신뢰 영역 최적화 알고리즘이다. DeepMind는 Gopher에 대해 유사한 보상 설정을 사용했지만 동기식 어드밴티지 actor-critic(A2C)을 사용하여 그레이디언트를 최적화했다. 이는 기존 방식과는 현저하게 다르지만 다른 테스크에서 재사용되지 않았다.
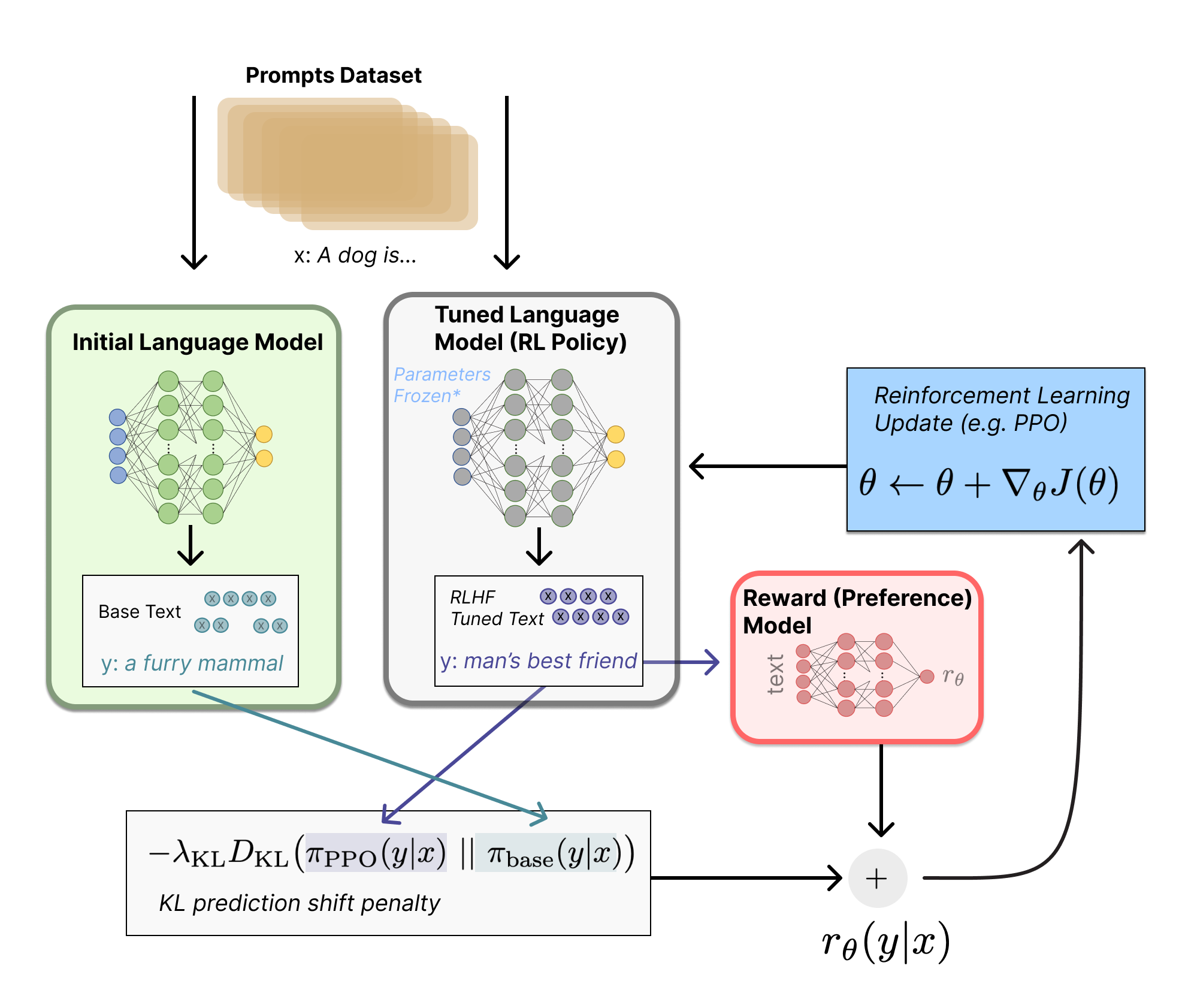
추가적으로, RLHF는 보상 모델과 정책을 함께 반복적으로 업데이트하여 지속할 수 있다. RL 정책이 업데이트됨에 따라 사용자는 모델의 이전 버전과 비교하여 출력 순위를 계속 지정할 수 있다.
위 글은 Huggingface에 나와있는 "Illustrating Reinforcement Learning from Human Feedback (RLHF)"글을 이해한대로 번번역한 글 입니다.
'Natural Language Processing > Large Language Model (LLM)' 카테고리의 다른 글
| [Paper 간단 리뷰] Platypus: Quick, Cheap, and Powerful Refinement of LLMs (0) | 2023.08.18 |
|---|---|
| [LLM 평가 지표] Elo Ratings으로 LLM모델들을 랭킹하는 방법 (1) | 2023.07.03 |
| [LLM] LLaMA 공개 이후 - #Self-Instruct #Alpaca (4) | 2023.06.09 |
| [LLM 모델 간단 Review] LLaMA: Open and Efficient Foundation Language Models (0) | 2023.06.08 |
| [강의 후기] 한국어 LLM 민주화의 시작 KoAlpaca! - 이준범 (0) | 2023.06.01 |



댓글