Question Answering 방식은 Method 관점과 Domain 관점으로 분류할 수 있다.
Question Answering - Method
Method에 기반한 QA 방식은 Extraction-based와 Generation-based로 카테고리를 나눌 수 있다.
Extraction-based QA
- Context 내에 질문에 대한 답변이 존재
- Context 내 답변이 위치하는 start/end token의 위치를 예측하는 등의 분류 수행
- 정답과의 Exact Match (EM), F1 score로 평가
Example)
Quesion: 북태평양 기단과 오호츠크해 기단이 만나 국내에 머무르는 기간은?
Context: 올여름 장마가 17일 제주도에서 시작됐다. 서울 등 중부지방은 예년보다 사나흘 정도 늦은 이달 말께 장마가 시작될 전망이다.17일 기상청에 따르면 제주도 남쪽 먼바다에 있는 장마전선의 영향으로 이날 제주도 산간 및 내륙지역에 호우주의보가 내려지면서 곳곳에 100㎜에 육박하는 많은 비가 내렸다. 제주의 장마는 평년보다 2~3일, 지난해보다는 하루 일찍 시작됐다. 장마는 고온다습한 북태평양 기단과 한랭 습윤한 오호츠크해 기단이 만나 형성되는 장마전선에서 내리는 비를 뜻한다.장마전선은 18일 제주도 먼 남쪽 해상으로 내려갔다가 20일께 다시 북상해 전남 남해안까지 영향을 줄 것으로 보인다. 이에 따라 20~21일 남부지방에도 예년보다 사흘 정도 장마가 일찍 찾아올 전망이다. 그러나 장마전선을 밀어올리는 북태평양 고기압 세력이 약해 서울 등 중부지방은 평년보다 사나흘가량 늦은 이달 말부터 장마가 시작될 것이라는 게 기상청의 설명이다. 장마전선은 이후 한 달가량 한반도 중남부를 오르내리며 곳곳에 비를 뿌릴 전망이다. 최근 30년간 평균치에 따르면 중부지방의 장마 시작일은 6월24~25일이었으며 장마기간은 32일, 강수일수는 17.2일이었다.기상청은 올해 장마기간의 평균 강수량이 350~400㎜로 평년과 비슷하거나 적을 것으로 내다봤다. 브라질 월드컵 한국과 러시아의 경기가 열리는 18일 오전 서울은 대체로 구름이 많이 끼지만 비는 오지 않을 것으로 예상돼 거리 응원에는 지장이 없을 전망이다.
Answer: "한 달"
Prediction: start-487, end-488
Generation-based QA
- Question과 context가 주어졌을 때, 적절한 답변을 생성 (generate)
- 정답과의 Exact Match (EM), F1 score로 평가
Example)
Quesion: 북태평양 기단과 오호츠크해 기단이 만나 국내에 머무르는 기간은?
Context: 올여름 장마가 17일 제주도에서 시작됐다. 서울 등 중부지방은 예년보다 사나흘 정도 늦은 이달 말께 장마가 시작될 전망이다.17일 기상청에 따르면 제주도 남쪽 먼바다에 있는 장마전선의 영향으로 이날 제주도 산간 및 내륙지역에 호우주의보가 내려지면서 곳곳에 100㎜에 육박하는 많은 비가 내렸다. 제주의 장마는 평년보다 2~3일, 지난해보다는 하루 일찍 시작됐다. 장마는 고온다습한 북태평양 기단과 한랭 습윤한 오호츠크해 기단이 만나 형성되는 장마전선에서 내리는 비를 뜻한다.장마전선은 18일 제주도 먼 남쪽 해상으로 내려갔다가 20일께 다시 북상해 전남 남해안까지 영향을 줄 것으로 보인다. 이에 따라 20~21일 남부지방에도 예년보다 사흘 정도 장마가 일찍 찾아올 전망이다. 그러나 장마전선을 밀어올리는 북태평양 고기압 세력이 약해 서울 등 중부지방은 평년보다 사나흘가량 늦은 이달 말부터 장마가 시작될 것이라는 게 기상청의 설명이다. 장마전선은 이후 한 달가량 한반도 중남부를 오르내리며 곳곳에 비를 뿌릴 전망이다. 최근 30년간 평균치에 따르면 중부지방의 장마 시작일은 6월24~25일이었으며 장마기간은 32일, 강수일수는 17.2일이었다.기상청은 올해 장마기간의 평균 강수량이 350~400㎜로 평년과 비슷하거나 적을 것으로 내다봤다. 브라질 월드컵 한국과 러시아의 경기가 열리는 18일 오전 서울은 대체로 구름이 많이 끼지만 비는 오지 않을 것으로 예상돼 거리 응원에는 지장이 없을 전망이다.
Answer: 한 달가량
Prediction: 한 달가량
Question Answering - Domain
Domain에 기반한 QA 방식은 Closed-domain과 Open-domain으로 카테고리를 나눌 수 있다.
Cloased-domain QA
- 미리 정의된 도메인에 속하는 질문에 대해 답변 (e.g. 의료, 금융)
- Example) 1억을 대출받으려는데 이자율은 얼마인가요?
- 질문이 정형화 되어 있음
- Domain-specific ontology 등에 의존
Open-domain QA
- 넓은 도메인에 속하는 질문에 대해 답변
- General ontology & world knowledge에 의존 (예를들어, wikipedia)
QA의 다양한 방식 중 Open-domain QA에 대해 자세히 알아보려고 한다. Open-domain QA는 크게 4가지로 분류할 수 있다.
- Retriever-Reader
- End-to-End
- Retrieval-Free
- Text & KB
본격적인 설명에 들어가기에 앞서 Retriever, Reader, Generator에 대해 간략히 짚고 넘어가려고 한다.
- Retriever에 대해 간략하게 설명하자면,
- Retriever은 Question과 관련된 Passage를 KB (ex.Wikipedia)에서 찾는 모델이다.
- 예를들어, BM25가 있고, Encoder구조를 활용할 수 도 있다.
- Reader에 대해 간략하게 설명하자면,
- Reader는 Passage에서 Answer 후보가 될 수 있는 Span을 찾는 모델이다.
- Encoder 구조로 되어있다.
- Generator에 대해 간략하게 설명하자면,
- Passage와 Question을 입력으로 하여 Answer을 생성하는 모델이다.
- Encoder-Decoder구조로 BART, T5, GPT 모델등이 있다.
Retriever-Reader

- Pipeline은 위 두 모델을 활용해 구성할 수 있다.
- Retrieval을 통해 Wikipedia같은 곳에서 문서를 검색한 다음 수집한 문서 내에서 정답을 예측한다.
- Retrieval는 별도의 학습 과정이 없다.
- TF-IDF 기반의 heuristic 방법론을 사용하여 매칭할 수 있다.
- Document Reader부분에서 딥러닝이 활용 될 수 있다.
- 학습 시 (question, context, answer) 3가지가 필요하다.
End-to-End
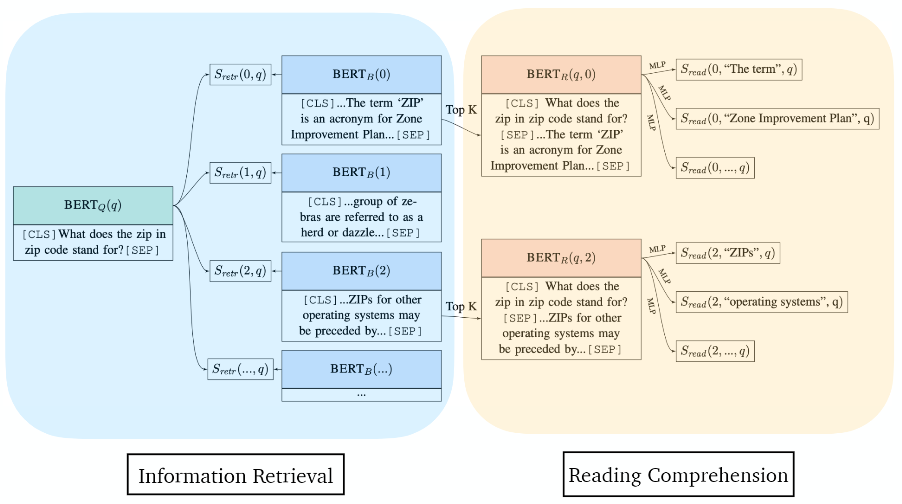
- Retriever까지 학습 가능한 BERT 기반의 구조를 의미한다.
Latent Retrieval for Weekly Supervised Open Domain Question Answering (2019)
- 많은 open corpus를 block 단위로 나누고, pretrained BERT로 임베딩을 미리 계산하여 빠르게 top-k document 검색을 수행
- 이때, Inverse Cloze Task (ICT) 사전학습 후 finetuning 시 passage encoder를 freezing한다.
- passage같은 경우에는 미리 임베딩이 되어있는 정보라 빠르게 계산할 수 있기 때문이다.
- 벡터간 유사도를 구하기 위해 facebook의 faiss를 활용할 수 있음
- 별도의 context 없이 (question, answer) 쌍으로만 학습
Dense Passage Retrieval for Open-Domain Question Answering (2020)
- 좋은 retriever는 좋은 QA 성능을 보인다.
- Lexical matching 기반(tf-idf 같은) (sparse) retrieval은 overlapped context에서 좋은 효과를 보인다.
- Dense retrieval은 의미적인 유사성을 잘 포착하는 경향이 있다.
- 이전 Latent Retrieval에서 수행하는 사전학습은 비용이 많이 들고, context encoder를 고정시키는 것은 최적화되지 않은 즉, suboptimal한 학습 방법이다.
- 따라서 DPR에서 제안한 방식은 Positiva passage와의 유사도는 높게, negative passage와의 유사도는 낮게 학습하도록 한다.
- 활용한 방식
- Hard negative passage
- Negative passage를 random하게 추출, BM25기반으로 추출 (정답은 포함하지 않지만, 질문 토큰을 가장 많이 포함하는 wiki추출), Gold기반으로 추출 (다음 질문에 대해 positive passage인 샘플을 추출하여 현재 질문의 negative passage로 활용)
- In-batch negative
- 현재 질문이 아닌, 다른 질문에 대해서 나온 positive passage와 negative passage를 현재 질문에 대한 negative passage로 활용하는 방법
- Hard negative passage
Retrieval-Free
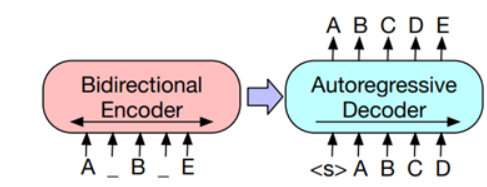
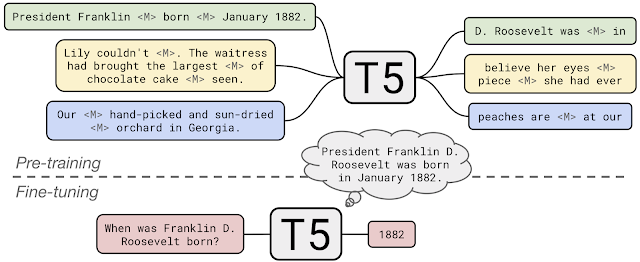
- Retrieval이 별도로 존재하지 않는다. Generator라고 볼 수 있으며, Passage와 Question을 입력으로 하여 Answer를 생성하는 모델이다.
- 학습된 언어 모델이 open corpus의 knowledge를 보유하고 있다는 가정 (closed book)
- Encoder-Decoder구조로 T5, BART, GPT 모델이 해당 카테고리에 포함된다.
Text & KB
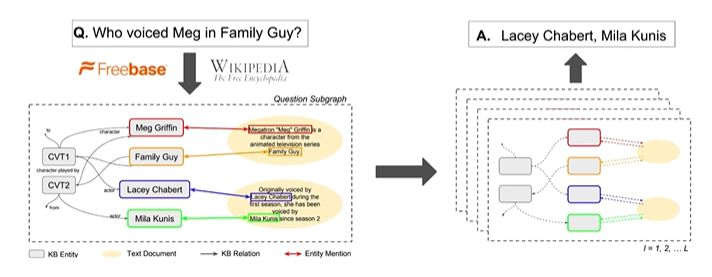
- Knowledge base (KB)와 텍스트를 모두 활용
- 텍스트: 범위가 넓으나 정보 검색이 어렵다.
- KB: 범위가 좁으나 정보 검색이 쉬움
- 위 두 장점을 활용해 텍스트 + KB의 knowledge를 포함하는 subgraph를 구축하여 질문에 대한 정답을 추출한다.
해당 글은 하단의 게시글과 영상을 기반으로 작성된 글 입니다.
Reference
* https://github.com/danqi/acl2020-openqa-tutorial
GitHub - danqi/acl2020-openqa-tutorial: ACL2020 Tutorial: Open-Domain Question Answering
ACL2020 Tutorial: Open-Domain Question Answering. Contribute to danqi/acl2020-openqa-tutorial development by creating an account on GitHub.
github.com
'Natural Language Processing > Question Answering' 카테고리의 다른 글
| [Paper 간단 리뷰] Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks (0) | 2023.08.25 |
|---|---|
| [ODQA] RAG 이후 간단 리뷰 (0) | 2023.08.11 |
| [ODQA] DRQA, ORQA, REALM 간단한 설명 (0) | 2023.08.05 |
| [Paper Review] Dense Passage Retrieval for Open-Domain Question Answering 란 (0) | 2023.06.28 |




댓글