Background
- ORQA가 등장하기 전에는 TF-IDF/BM25를 능가하는 Dense Retrieval이 없었다.
- 하지만 ORQA 역시 약점을 가지고 있다.
- ICT(inverse cloze task) pre-training을 활용하였는데 이 방식은 연산량이 많다.
- ORQA의 경우 BERT로 쪼개진 wiki문장에서 10%의 임의 문장을 가져오는데, 이 문장이 질문으로 적합한지가 애매하다.
- Passage Encoder를 fine-tuning하지 않기 때문에, 이는 최적화된 방법이 아니다.
Question과 Passages(or Answer)만 가지고 추가적인 pretraining없이 더 나은 dense embedding model을 학습할 수 있을까?
위 질문을 기반으로 Dense Passage Retriever가 제안되었다.

- Retrieval에서의 Backbone Model은 BERT를 활용하였다.
- open-domain QA에서 retrieval component를 향상시키는데 집중했다.
- M개의 passage가 주어졌을 때 모든 passage에 대한 index를 연속적인 저차원 공간에 매핑하는 것이 목적이며, Inference시에는 Question Encoder와 Passage Encoder를 활용하였다.
- Dense Encoder E_p를 사용하는데 이것은 d차원의 실수 벡터로 passage를 매핑하고 모든 M개의 passage에 대해서 인덱싱을 한 다음, 우리가 retrieval에 사용할 수 있도록 한다.
- Inference가 될 때에는, Dense Encoder E_q를 활용하는데 이것은 입력으로 받은 질문을 d차원의 실수 벡터로 매핑하고 질문벡터와 가장 유사한 k개의 벡터를 검색한다. 이때, 질문과 지문의 유사도를 벡터 내적을 사용해 정의할 수 있다.

- 위 과정을 통해 질문과 연관된 top-k 개의 passage를 효과적으로 추출할 수 있다. (k:20-100)
- Inference 단계에서는
- Faiss 라이브러리를 사용하여 passage encoder의 임베딩 벡터를 미리 계산한다.
- 새로운 질문이 입력으로 들어왔을 때 연관된 passage를 빠르게 반환한다.
- 질문 q가 주어지면, E_Q에 q를 입력해 임베딩 v_q를 얻는다. 그리고 v_q와 유사한 상위 k개의 지문을 탐색한다.
Training
연관된 question-passage 끼리 가까운 공간에 휘치하는 vector space를 구축하는것을 목적으로 한다.
즉, vector space를 구축해서 더 좋은 임베딩 함수를 학습함으로써 질문과 지문쌍의 유사도가 높다면 관련이 없는 쌍보다 더 적은 거리를 가지게 되도록 하는 것이다.

위는 m개의 인스턴스로 구성되어 있는 학습데이터이다. 각각의 인스턴스는 어떠한 질문 q_i와 이와 관련된 긍정 지문 p_i+ 관련이 없는 n개의 부정 지문 p_ij-로 이루어져 있다. 논문에선 관련 지문의 NLL Loss를 사용하여 최적화 하려고 한다.

Positive/negative passage
Retrieval은 positiva example은 명확하게 존재하지만, negative example은 매우 큰 데이터셋에서 선택되어야 한다는 것이다. 이때, negative example은 인코더를 높은 품질로 학습하는데 활용되는 요소기 때문에 아래와 같이 3가지 negative type을 고려해야 한다.
- BM25: 정답을 포함하지 않으면서, 질문에 대해 가장 많은 토큰을 포함하는 문장을 추출하는 것이다.
- Random: 랜덤하게 아무 passage를 추출하는 것이다.
- Gold: 다른 질문에 대한 positive passage를 추출하는 것이다.
In-batch negatives
해당 방식은 모델이 학습시 샘플의 수를 늘린다(재사용성)는 점에서 효과적인 방법이다.

미니 배치에 B개의 질문이 있다고 하면, 각각의 질문(Q)은 유사도가 있는 특정 passage(P)와 관련이 있다고 가정하자. B개의 질문 Q는 B*d차원으로 이루어져 있고, 이에 대응하는 passage P또한 B*d차원으로 이루어져 있을 것이다. 이때, passage을 transpose하여 Q*P^T로 변환해주면 B*B 크기의 행렬을 가질 수 있다. 각각의 행은 B개의 passage와 질문의 쌍을 이루게 된다. 이 방법을 활용해 B^2 질문/passage 쌍을 각각의 배치에서 학습할 수 있다. 따라서 각각의 행과 열이 같을때는 positive로, 다를 때는 negative관계를 갖도록 학습을 진행할 수 있다.
Experiment
Datasets
- Natural Question (NQ): End-to-End QA를 위해 만들어 진 데이터 셋이다. 구글 검색 질문에서 데이터 셋을 수집했고, 답변은 위키피디아 기사에서 발췌했다.
- Trivia QA: 사소한 질문 답변들로 구성되어 있으며 웹 페이지에서 가져왔다.
- WebQuestion (WQ): 구글 API에서 사용해 선택된 질문과, 이 API의 Freebase안에 존재하는 정답으로 구성되어 있다.
- CuratedTREC (TREC): 다양한 웹의 출처를 가지고 있어 구조화되어있지 않은 말뭉치로부터 ODQA task를 위해 수집되었다.
- SQuAD v1.1: 위키피디아 지문을 받고 주어진 지문으로 부터 답변이 작성된 데이터 셋이다. (이때, 해당 데이터는 ODQA 연구에 이상적인 데이터 셋은 아니다.)

Passage Retrieval
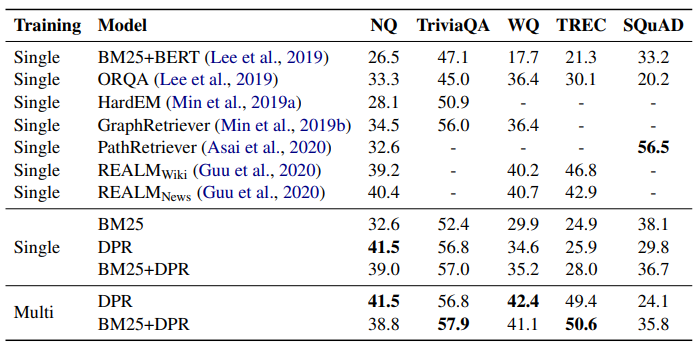
해당 연구에서 사용되는 DPR 모델은 BM25를 이용해 얻은 negative passage들을 128개의 batch size로 하는 in-batch negative를 설정해 학습한다. 또한 BM25와 선형결헙을 통해 새롭게 점수를 매긴 BM25+DPR 결과도 제안한다. BM25와 DPR을 각각 기준으로 한 상위 2천개의 시작 세팅을 구성했다. 그리고 BM25+DPR의 경우 를 랭킹 함수로 사용해서 이들을 다시 평가했다.
이때, retrieval accuracy는 검색된 passage 안에서 해당 question의 gold passage가 있는지 체크하는 것이 아니라
answer span이 포함된 passage가 있는지 체크한 accuracy다.

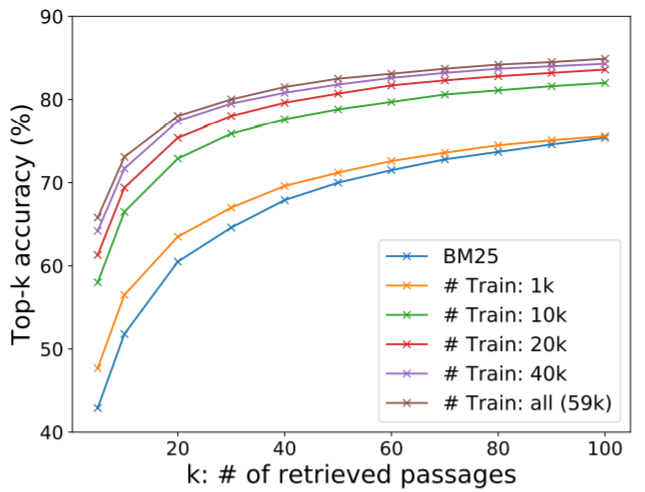
Sample efficiency
SQuAD를 제외한 모든 데이터셋에서 DPR은 BM25보다 좋다. k가 커질수록 성능 차이는 커진다.
In-batch negative training
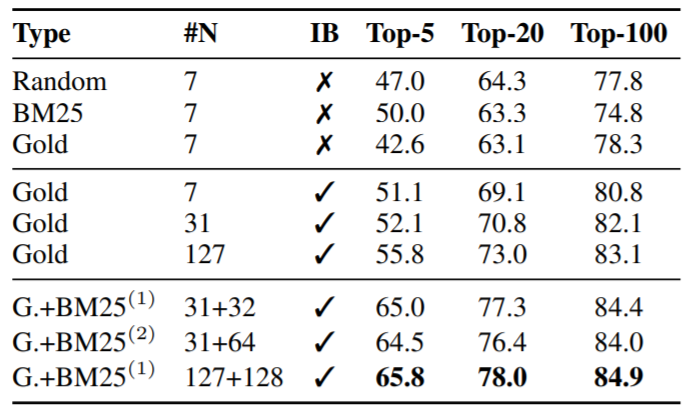
- k=20 이상일 경우 negative passage의 종류는 크게 연관이 없다.
- In-batch negative가 성능 향상에 효과적이다.
- 배치 크기가 클수록 정확도가 향상된다.
- BM25를 활용한 추가 negative passage가 batch내 모든 질문에 대해 negative passage로 적용한 것이 성능이 제일 높다.
Question Answering (Exact Match score)
해당 글은 하단의 영상과 나와있는 글을 참고해 작성한 글 입니다.
'Natural Language Processing > Question Answering' 카테고리의 다른 글
| [Paper 간단 리뷰] Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks (0) | 2023.08.25 |
|---|---|
| [ODQA] RAG 이후 간단 리뷰 (0) | 2023.08.11 |
| [ODQA] DRQA, ORQA, REALM 간단한 설명 (0) | 2023.08.05 |
| [QA task] QA task, Open-domain QA (0) | 2023.06.27 |




댓글