728x90
Open Domain Question Answering (ODQA) vs Konwledge-Intensive Task (KIT)
- ODQA: 연속된 토큰 (Continuous Span)으로 Answer 존재 가능 (항상 그런것은 아님)
- KIT: Passage 내 Answer 토큰이 존재하지 않음
ODQA의 연구 흐름

- RAG는 이전 ODQA 연구를 연결하여 Knowledge Intensive Task로 확장한다.
- RAG 이후 연구인 FiD ~ Atlas는 RAG 기반이다.
DrQA

- 질문이 주어졌을 경우, Wikipedia로부터 passage로 활용할 수 있는 k개의 후보 문서를 가져온 다음, 가져온 passage와 question을 Reader의 입력으로 활용하여 Answer를 산출하는 방식이다. (이때, Reader를 학습시켜 Answer를 뽑아낸다.)
- Passage가 없더라도 KB(외부 지식)으로부터 BM25, TF-IDF, Wikipedia Search Engine 등을 통해 빠르게 Passage를 탐색할 수 있다.
- 하지만, Retrieval은 BM25 혹은 검색 엔진으로 활용되었기 때문에 성능 개선이 불가능했다.
ORQA
위에 언급한 DrQA를 개선한 논문이 ORQA이다.
- Retriever 학습에 필요한 signal은 ORQA에 의해 처음 정의되었다.
- Retriever 은 두가지 Encoder로 구성되어 있다.
- Passage Encoder: Pretrain (ICT)를 통해 학습, Finetuning시에는 freeze돼서 활용된다.
- Question Encoder: Pretrain과 Finetune을 통한 학습이 이루어진다.
- Finetune 시 두가지 방식으로 Retriever을 훈련한다.
Passage Retrieval과정

- Passage retrieval과정에서 이루어진다. KB로부터 상위 k개를 추출한 다음, Answer span을 포함하고 있는 passage의 likelihood를 최대화하도록 학습을 진행하면 된다.
Finetune 시 두가지 방식으로 Retriever를 훈련

- Answer Span prediction과정에서 retrieval이 직접적으로 들어와 학습이 진행된다.
- Answer Span의 likelihood를 최대화 하도록 훈련이 진행된다.
- Passage가 Reader를 통과한 retrieval score 값과, 원래의 retrieval score 값이 softmax에 통과되어 계산이 이루어지게 된다.
REALM


- MLM을 Pretrain 태스크로 사용하였다.
- ORQA와 다르게 Retrieval시 별도의 annotation을 사용하지 않았다. (ORQA에서는 Passage내에 Answer span이 존재하는지 판단해 annotation을 진행했지만 해당 논문에선 별도의 annotation없이 학습이 이루어질 수 있다는 것을 제시함)
- Masking의 경우 Answer로 사용될 가능성이 높은 entity(인명, 지명 등)을 masking함으로써 masking된 토을 복원하는 과정으로 학습이 이루어지게 된다.
- 즉, 학습 과정에서 첫번째 그림과 같이 <mask>처리가 된 Question이 입력이 되면, Retrieval을 거쳐 뽑힌 K개의 Passage와 결합해 Reader의 입력으로 보내 <mask>된 답변을 추출하도록 학습이 이루어 진다.
좀 더 자세히 보자면,

- Question이 입력되고, Retrieval score를 기준으로 상위 K개를 추출하게 된다.
- 각각의 Passage는 Reader를 거쳐 Reader score값을 뽑은 다음 Softmax 값을 취해 likelihood 를 뽑고, Retrieval score 는 softmax를 거쳐 liklihood를 산출한다. 그 다음, 두개의 likelihood 값을 활용하여 Answer likelihood 를 계산하게 된다.
- 따라서 Answer likelihood 는 Passage의 확률 분포와 Answer에 대한 Passage의 liklihood로 분해될 수 있다.
- MLM을 활용한 Pretrain시에는 annotation을 활용하지 않았지만, Finetune시에는 Passage에 대한 Annotation을 활용한다. 따라서 Gold Passage에 대한 likelihood 값을 높이도록 학습한다.
이때, REALM이 Pretrain시 MLM을 이용할때, Passage에 대한 Annotation이 사용되지 않는데 어떻게 학습이 이루어 질까?
Reader가 MLM 수행 시 직접 Retriever에게 Signal을 전달하도록 변경했기 때문이다.
이때, Signal은 Answer의 likelihood 가 아래의 식과 같이 구성되어있을 때,
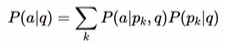
Answer log likelihood 의 Retriever에 대한 편미분으로 보면 "리워드" 값과 "Retrieval의 편미분"이 곱해져있는 것을 볼 수 있다.
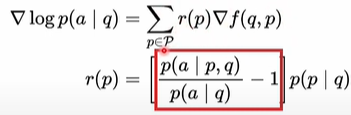
이때, 리워드 식을 보면 question이 입력되었을 때, passage에 대한 분포로 분해가될 수 있음을 볼 수 있다.
해당 식을 좀 더 자세히 보자면,
- p(a|p,q): passage와 question이 주어졌을 때 answer에 대한 확률 값은 특정 passage가 사용됐을 때, answer에 대한 likelihood 값이라고 할 수 있다.
- p(a|q): question만 주어졌을 때, answer에 대한 확률 값은 랜덤한 passage를 latent variable로 사용했을 때, answer에 대한 liklihood값이라고 할 수 있다.
- 따라서, p(a|p,q) > p(a|q) 일 경우, 리워드에 양수의 signal이 전달되게 되고, 반대의 경우에는 음수의 signal이 전달되게 된다.
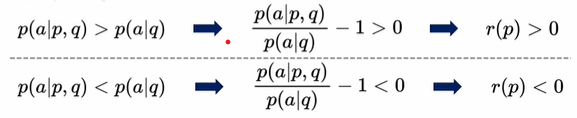
그러므로, 리워드값의 경우 "랜덤한 passage 사용 대비 특정 passage 사용 시 얻을 수 있는 likelihood 개선 비율"과 "query에 대해 passage에서 얻을 수 있는 likelihood 개선 기대값"을 곱한 값이라고 볼 수 있다.
따라서 Retriever업데이트 시 필요한 정보는 "Answer 추론 시 Passage가 도움이 되는 정도"라고 볼 수 있다.
ORQA vs REALM
언급한 위 두개의 모델에 대해 차이점을 파악해보면 다음과 같다.
| ORQA | REALM |
 |
|
| - Retrieval score와 Reader score를 더한 다음 softmax 값을 취했다. - 따라서 passage를 Latent Variable로 도입한 모델링이 불가능하다. |
- Retrieval score를 따로 softmax취하고, reader score를 따로 softmax를 취했다. - 따라서 passage를 Latent Variable로 도입한 모델링이 가능하다. |
아래 유투브 영상을 기반으로 작성된 글 입니다.
728x90
'Natural Language Processing > Question Answering' 카테고리의 다른 글
| [Paper 간단 리뷰] Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks (0) | 2023.08.25 |
|---|---|
| [ODQA] RAG 이후 간단 리뷰 (0) | 2023.08.11 |
| [Paper Review] Dense Passage Retrieval for Open-Domain Question Answering 란 (0) | 2023.06.28 |
| [QA task] QA task, Open-domain QA (0) | 2023.06.27 |




댓글