기존의 BERT와 RoBERTa 모델은 sentence classification과 sentence-pairregression task에서 SOTA를 달성했다. 하지만, sentence similarity를 탐색하는 task에서는 두 개의 문장을 network에 입력해야 하고, 많은 연산량을 요구하게 된다.
따라서 위 문제점을 해결하기 위해, siamese/triplet network를 이용하여 보완한 SBERT 방법을 제안한다.
Introduction
위에서도 잠깐 언급했지만, BERT와 RoBERTa 모델이 sentence-pairregression task에서 SOTA를 달성했지만, 두 개의 문장이 transformer network입력으로 들어가게 되므로(cross encoder) 오버헤드가 발생하게 된다.
쉽게 풀어서 설명하자면, 10,000개의 문장 쌍을 비교한다고 가정할 때, BERT는 n(n-1)/2 = 49,995,000번의 계산을 수행해야한다. 이 방식은 V100 GPU를 사용한다고 하더라도 약 65시간 정도 소요되는 연산량이다.
연산량 뿐만 아니라, 문장 쌍을 비교하기 위해 문장을 vector space에 mapping해 의미적으로 비슷한 문장에 가깝게 만들어 주어야 한다. BERT의 경우 문장 하나에 대해서 임베딩을 활용할 수 없기 때문에 [CLS] 토큰 출력을 받거나 혹은 output layer로 부터 고정된 크기의 문장 embedding을 평균 내서 결과를 도출해야 한다. 하지만 이 방식의 경우 GloVe embedding을 평균내는 방법보다 성능이 떨어진다고 한다.
주요 Contribution
- BERT에 siames/triplet network를 이용해, semantically meaningful 문장 임베딩을 가능하도록 했다.
- 10,000개의 문장 쌍에 대한 임베딩의 경우 5초 이내로 연산 가능하며, cosine similarity도 0.01초 이내로 연산 가능하다.
- Semantic Textual Similarity task의 경우 InferSent보다 11.7의 좋은 성능을 보였다.
- Specific task에도 적용할 수 있다.
- 이전의 neural sentence embedding은 random initialization에서 학습을 시작하는데, SBERT의 경우 pre-trained BERT/RoBERTa에 fine-tuning하여 학습한다.
Model
SBERT는 고정된 크기의 문장 embedding을 얻기 위해 아래와 같이 3가지 pooling 방법을 비교한다.
- [CLS] 사용
- Output vector들의 평균 값 (모든 벡터들에 대해 평균)
- Output vector들의 최대 값 (각 토큰 임베딩 중 가장 max인 값 추출)
Pooling에 대한 실험결과는 아래와 같으며, STS에서 평균 값을 활용한 성능이 가장 좋다고 한다. (Classification의 경우 pooling 방법에 대한 차이가 미미했다고 한다.)

BERT와 RoBERTa를 fine-tuning하기 위해 siamese와 triplet network 구조를 활용한 다음, 생성된 문장 embedding에 대하여 cosine-similarity를 연산해 가중치를 업데이트 했다. Siamese와 triplet network 구조는 학습 데이터에 따라 달라지기 때문에 3가지 목적함수에 대해 실험을 진행했다.
Classification Objective Function

Sentence A,B에 대한 embedding u와 v를 |u-v|와 concatenation한 다음, 학습 가능한 가중치 (아래 이미지에서 W_t)를 곱하여 objective function을 만든다.


이때, n은 embedding dimension이고 k는 label의 갯수 이다. 그 다음, cross-entropy loss를 활용해 최적화 한다.
Regression Objective Function
AFS, STS에서 사용하는 objective function이다.

Sentence A,B에 대한 embedding u와 v의 cosine similarity를 구한다. 그 다음 MSE loss계산을 통해 최적화 한다.
Triplet Objective Function
기준이 되는 문장 a와 a에 대한 유사한 문장 p와 유사하지 않은 문장 n이 주어졌을 때, a와 p사이의 거리가 a와 n 사이의 거리보다 더 가깝도록 triplet loss를 계산한다.

Experiment
Training Details
SBERT를 SNLI와 Multi-Genre NLI dataset으로 학습시킨다. SBERT는 한 epoch으로 3-way softmax-classifier objective function(label이 3개)을 통해 학습한다. Batch size는 16으로 Adam optimizer와 learning rate는 2e-5로 설정했으며, 학습 데이터의 10%에 대해 linear learning rate warm-up을 적용했다.
Evaluation - Semantic Textual Similarity
SBERT에서 cosine-smiliarity를 사용하여 두 문장간의 유사도를 비교한다. 다른 distance metric인 negative Manhatten/Euclidean distance로도 실험했지만, 코사인 유사도와 비슷한 성능을 냈다.
Unsupervised STS
STS에 대해 학습하지 않고 실험한 결과이다.

피어슨 상관계수는 STS에서 사용하기 좋지 않기 때문에 문장 임베딩과 레이블간의 코사인 유도에 대해 스피어만 상관계수로 성능을 비교했다. SBERT의 성능이 제일 좋았다.
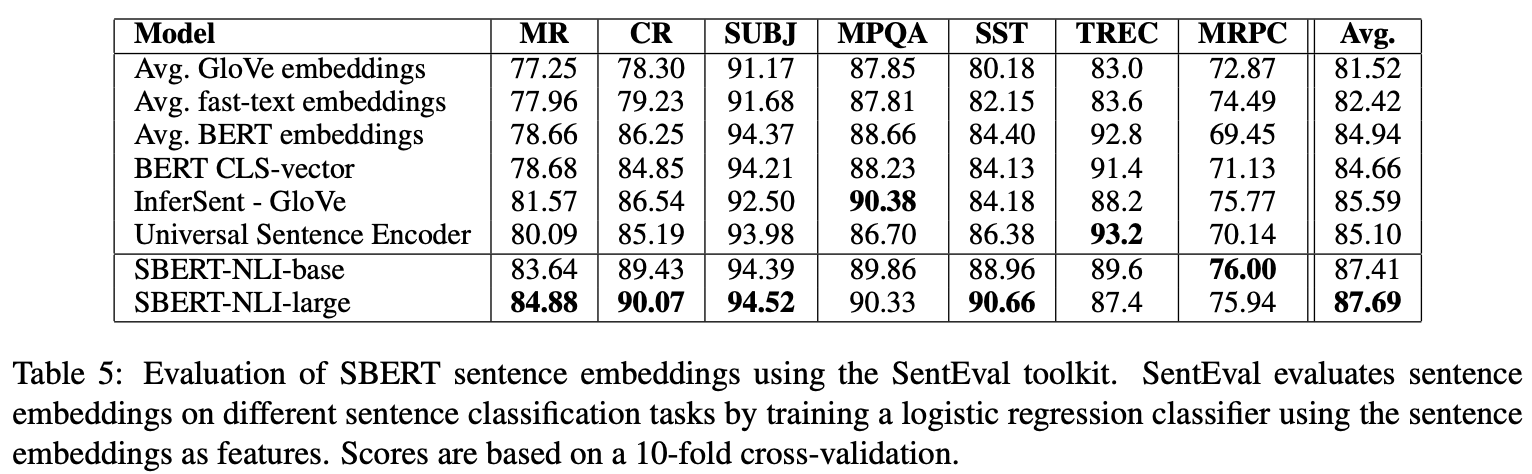
Supervised STS
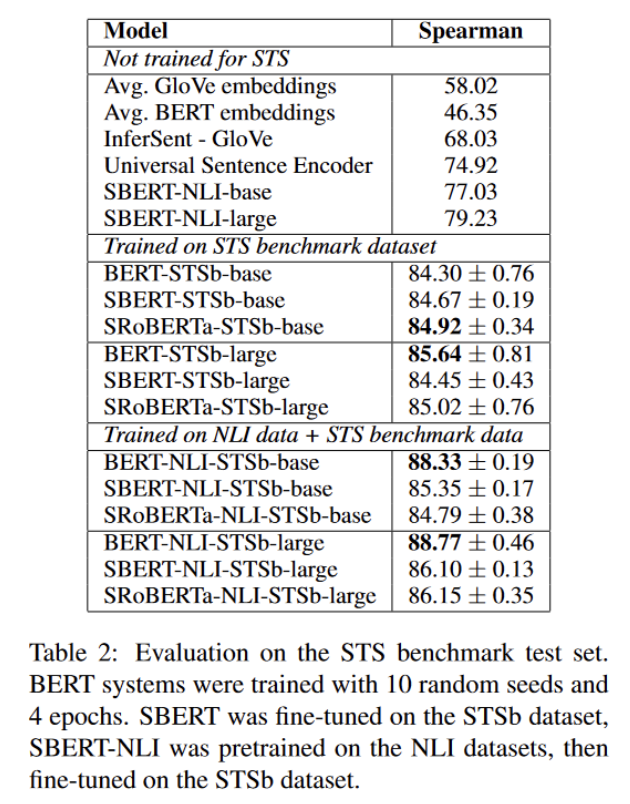
Argument Facet Similarity
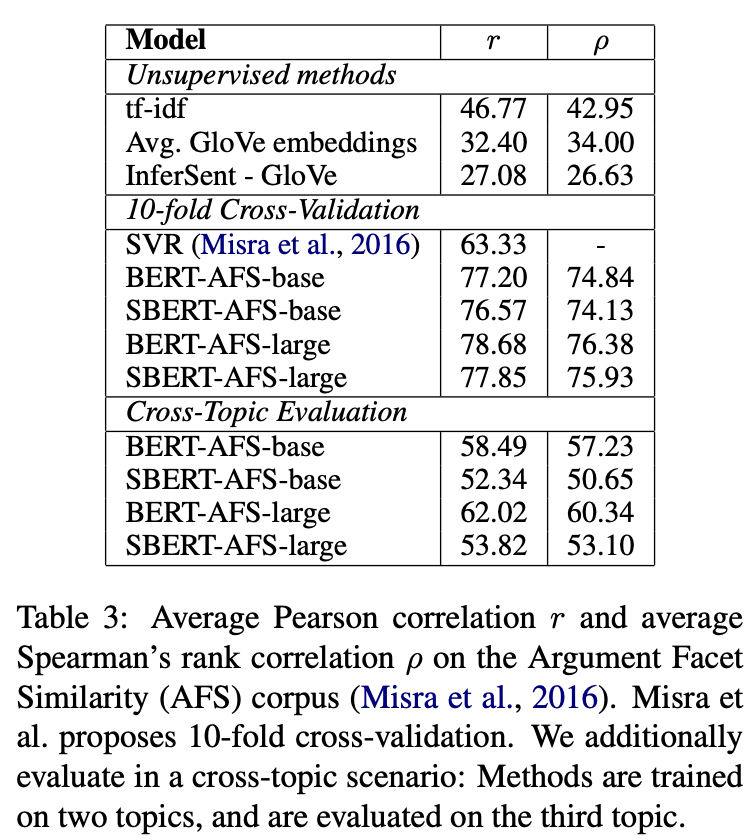
Wikipedia Section Distinction
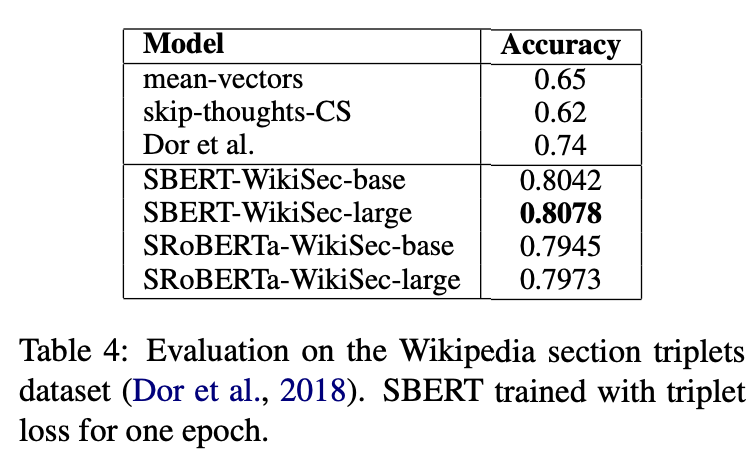
Evaluation - SentEval
'Natural Language Processing > Question Answering' 카테고리의 다른 글
| [ODQA] RAG 이후 간단 리뷰 (0) | 2023.08.11 |
|---|---|
| [ODQA] DRQA, ORQA, REALM 간단한 설명 (0) | 2023.08.05 |
| [Paper Review] Dense Passage Retrieval for Open-Domain Question Answering 란 (0) | 2023.06.28 |
| [QA task] QA task, Open-domain QA (0) | 2023.06.27 |




댓글